|
|
Administrators accustomed to the methods, tools, and parameters used to monitor and improve performance on OpenServer 5 (OSR5) systems will need to become familiar with those used on OpenServer 6 (OSR6). Although many of these methods, tools, and parameters are similar to those used in OSR5, an OSR6 system cannot be tuned in exactly the same way as an OSR5 system, and achieve similar performance goals.
For an idea of the tuning distinctions between the two systems, see the OSR5/OSR6 Tunables Comparison, which compares just the kernel tunable parameters for the two releases. For some OSR5 parameter groups, there are rather direct equivalents on OSR6. For others, there are many obsolete and new parameters. And, in addition to the parameter groups from OSR5 discussed in the table, there are many new parameter groups that control resources that did not exist on OSR5.
In this document, we review the sections of the OSR5 Performance Guide (available at: http://osr507doc.sco.com/en/PERFORM/CONTENTS.html), and summarize the differences between OSR5 and OSR6 tuning, what you need to do on OSR6 to monitor and tune those resources, and provide references to related new OSR6 tunables.
See also:
OpenServer 6 is a multiprocessing operating system that provides a full set of tools for examining CPU activity and making adjustments to the kernel so that CPU resources are used efficiently.
The procedures and tools used on OSR6 to monitor and tune CPU resources are described in the Managing system performance chapter.
Note the following:
Hyper-Threading (Hyperthreading, or HT) Technology allows two series of instructions to run simultaneously and independently on a single Intel Xeon or HT-enabled Intel Pentium 4 processor. With hyperthreading enabled, the system treats a physical processor as two ``logical'' processors. Each logical processor is allocated a thread on which to work, as well as a share of execution resources such as cache memories, execution units, and buses.
Multiple core processors have two or more processor cores in each physical CPU package. (The number of internal processors may also be used in the processor name; for example, "dual core" processors.) This architecture continues the trend started with hyperthreading, adding enhanced parallelism and improved performance.
One critical difference between hyperthreading and multiple core processors is that multiple processor cores are detected automatically and utilized if available; hyperthreaded processors, on the other hand, are not utilized unless the administrator specifically requests their use.
The use of multiple processor cores is enabled by default. To disable it, enter the MULTICORE=N boot parameter at the boot loader prompt (or add it to the /stand/boot file). If the use of multiple processor cores is explicitly disabled, then the use of hyperthreading is also disabled. (Having multiple core support enabled has no effect on systems that do not have multiple core processors.)
Note that on some systems (particularly where multi-core processors are included in the system's MPS tables), ACPI=Y must be entered in addition to MULTICORE=N to disable the use of multiple cores.
Hyperthreaded processor support is disabled by default. Support for hyperthreaded processors can be enabled with any of the following boot parameters:
ENABLE_HT=Y ENABLE_JT=Y HYPERTHREAD=Y
These (and other) boot parameters are discussed on the hyperthread(HW) and boot(HW) manual pages.
Note that if your system supports hyperthreading, then hyperthreading should always be enabled in the system BIOS, regardless of the operating system setting.
Both AMD and Intel multiple core processors are supported. No additional CPU licenses are required to use either multiple processor cores or hyperthreaded processors.
On OSR5, an administrator affected process scheduling through the the tunable kernel parameter MAXSLICE (set the maximum time slice for a process; obsolete on OSR6), and by altering scheduler variables in the file /etc/conf/pack.d/kernel/space.c.
On OSR6, the process scheduler provides both a command-line interface and API. It provides much finer granularity in process scheduling than the OSR5 scheduler. See the Process Scheduling chapter of Monitoring and Tuning the System for a full description.
See the sections: ``Timer and scheduler parameters'' and ``Processor cache affinity parameters'' for kernel tunable parameters that affect CPU performance.
Both OSR5 and OSR6 are Virtual Memory systems, but OSR6 offers greater flexibility in the way in which memory can be configured. OSR6 also supports large memory configurations of up to 64GB of physical memory. Up to 16GB for General Purpose Memory and up to 64GB as Dedicated Memory is supported. Dedicated memory is limited for use as either Shared Memory (SHM) or Dynamic Shared Memory (DSHM).
Whenever the system is rebooted the size of these areas, as well as the total amount of physical memory, is logged in the file /var/adm/messages:
536346624 bytes of memory were detected.
536334336 bytes of memory are in use.
518361088 bytes of general purpose memory are available.
0 bytes of memory are dedicated.
If your system has more than 4GB of physical memory, see !U ??? for how to configure your system to use the memory above 4GB.
During installation, the system configures virtual memory and swap space based on the amount of physical memory installed, and the size of all memfs filesystems defined. Many of the paging kernel parameters are also autotuned based on physical memory.
The Virtual Memory parameters are listed in the section ``Virtual memory (VM) parameters''. Most of these parameters should be left to their default or autotuned values, though in some situations, particularly to support large database systems, increasing the following tunables may improve performance:
All the Virtual Memory, Paging, and other VM-related kernel parameters are described in the section .
The number of 4K pages of unused memory is shown by sar -r:
14:00:00 freemem freeswap freekv filemem 14:20:00 83904 252778 90642 83904 14:40:00 83988 253001 90730 83988 15:00:36 44821 217537 89716 44821 15:20:17 18381 183138 89135 18381 15:40:21 18184 183482 89313 18184 16:01:34 38129 183077 89013 38129 16:20:05 43830 182760 88875 43830 16:40:05 40987 182928 88969 40987 17:00:00 82319 228318 89950 82319 17:20:00 101310 250733 90384 101310 Average 80041 238763 88113 80041
| freemem | free physical memory available to user processes |
| freeswap | free virtual memory (physical + swap) available to user processes |
| freekv | free address space available for kernel mappings |
| filemem | that part of freemem which can be used to cache file data |
Running rtpm and selecting the MEMORY group provides a more detailed look at virtual memory and the Kernel Memopry Allocator buffer pool (all memory values are in 4K pages):
60746 frmem 247359 frswpm 211004 frswpdsk 338364 swpmem 130944 mem
54 %mem 27 %swpmem 2 %swpdsk 214783 swpdsk 15298 kma
kmasz mem alloc req fail kmasz mem alloc req fail
16 262144 241216 137682 0 208 2609152 1583296 1326036 0
32 1409024 895168 730396 0 2720 344064 331840 312272 0
64 360448 158272 129096 0 400 389120 374800 293056 0
128 999424 961664 683881 0 736 131072 115552 94522 0
256 212992 120576 104249 0
512 114688 100352 90808 0
1024 10813440 6316032 4906968 0
2048 1900544 1857536 1794324 0
4096 860160 823296 659910 0 ovsz 21086208 21086208 20900248 0
8192 81920 65536 42416 0 total 41574400 35031344 32205864 0
| frmem | the amount of free memory in the system |
| %mem | the percentage of memory in use |
| frswpm | the amount of free swap memory in the system |
| %swpmem | the percentage of memory swap space in use |
| frswpdsk | the number of pages of free disk swap space in the system |
| %swpdsk | the percentage of disk swap space in use |
| swpmem | the number of swap memory pages in the system |
| swpdsk | the number of pages of disk swap space in the system |
| mem | the total number of memory pages in the system |
| kma | the total number of memory pages used by the kernel memory allocator (KMA) |
| kmasz | each line is a pool of memory used by KMA, divided up into buffers that are each kmasz in length |
| mem | the amount of memory reserved for the kma pool |
| alloc | the amount of memory allocated in the kma pool |
| req | the amount of memory requested from the kma pool |
| fail | the number of failed kma requests for the pool |
| ovsz | mem, alloc, req, and fail for the oversize pool |
| total | mem, alloc, req, and fail for all the above |
Basic information about the usage of the swap areas on your system can also be seen using the swap -l command:
path dev swaplo blocks free /dev/swap 7679,1 0 1718264 1688032
| path | The path name for the swap area. |
| dev | The major/minor device number in decimal if it is a block special device; zeros otherwise. |
| swaplo | The offset into the device where the swap area begins, in 512-byte blocks. |
| blocks | The length of the swap area, in 512-byte blocks. |
| free | The number of free 512-byte blocks in the area. This number does not include physical memory allocated to swapping. If the swap area is being deleted, the word INDEL will be printed to the right of this number. |
The swap -s command returns swap usage statistics:
total: 98312 allocated + 942000 reserved = 1040312 blocks used, 1666600 blocks available
| allocated | The amount of swap space (in 512-byte blocks) allocated to private pages. |
| reserved | The amount of swap space (in 512-bytes blocks) not currently allocated, but claimed by memory mappings that have not yet created private pages, or have created them but have not swapped them out. |
| used | The total amount of swap space (in 512-byte blocks) that is either allocated or reserved. |
| available | The total swap space (in 512-byte blocks) that is |
| currently available for future reservation and allocation. This number | |
| includes physical swap memory that is available (that is, the total | |
| swap memory less the amount currently in use). The sum of used and available will be larger than the sum of the swap slices because main memory may be used as effective swap space. |
14:00:00 swpin/s pswin/s swpot/s pswot/s vpswout/s pswch/s 14:20:00 0.00 0.0 0.00 0.0 0.0 82 14:40:00 0.00 0.0 0.00 0.0 0.0 82 15:00:36 0.09 0.1 0.14 120.3 184.3 723 15:20:17 0.19 0.2 0.19 10.7 16.6 990 15:40:21 0.19 0.2 0.19 12.3 21.9 1024 16:01:34 0.04 0.0 0.03 2.3 3.3 980 16:20:05 0.00 0.0 0.00 0.0 0.0 898 16:40:05 0.00 0.0 0.00 0.0 0.0 910 17:00:00 0.01 0.0 0.00 0.0 0.0 375 17:20:00 0.00 0.0 0.00 0.0 0.0 90 Average 0.01 0.0 0.01 3.6 5.6 234The column of interest is
pswot/s,
the average number of pages swapped out
per second during the sampling interval.
The ratios of pages to transfer requests per second
(pswin/s to swpin/s, and
pswot/s to swpot/s) show how many
pages could be moved between memory and disk per average
disk transfer.
For most systems, pswot/s should be 0 while the load is running stably, with occasional increases during heavy system loads. A consistent pageout load indicates memory pressure; the available memory cannot handle the system load.
If installed physical memory is under 1GB, adding physical memory may solve the problem. If 1GB or more of memory is already installed, then either the kernel or a user application is continually consuming more memory (sometimes called a "memory leak").
If a memory leak is present inside the kernel, then the amount of memory used by the Kernel Memory Allocator (KMA) will slowly and continually grow. Use the sar -k command to display a history of KMA usage.
If memory pressure is coming from the application, then the application's process size will continually grow over time. Monitor the output of ps -el to determine if this is happening. One common problem in application code is to allocate memory with malloc and then never free the memory. The application code needs to be updated so that unused memory is freed after use; or, more memory needs to be added to accommoate the needs of the application.
Similarly, if the swap queue shows activity, then there are processes being swapped out to make memory available. Swapping activity is also indicated by the size of the swap queue. The swap queue is a queue of runnable processes held in the swap area. Swapped-out processes are queued in an order determined by how long they have been swapped out. The process that has been swapped out for the longest period of time will be the first to be swapped in, as long as it is ready to run.
The values of swpq and %swpocc
displayed by sar -q
indicate the number of runnable processes on swap,
and the percentage of time that the swap areas were
occupied by runnable processes:
14:00:00 prunq %prunocc runq %runocc swpq %swpocc 14:20:00 14:40:00 15:00:36 1.2 34 2.5 6 2.8 23 15:20:17 1.1 83 4.4 2 1.8 37 15:40:21 1.1 85 2.2 2 2.2 44 16:01:34 1.2 17 7.5 1 1.4 8 16:20:05 1.4 8 1.6 9 16:40:05 1.3 11 1.1 24 17:00:00 1.6 3 5.8 0 1.7 1 17:20:00 1.0 0 Average 1.5 10 1.5 4 2.1 3If the entries for
swpq and %swpocc
when running sar -q remain blank then
no processes are being swapped and memory is sufficient.
If swpq is greater than zero, then the system
is swapping, and there are runnable processes in swap space.
Paging activity may slo indicate memory problems. You can see paging activity using sar -p:
14:00:00 atch/s atfree/s atmiss/s pgin/s ppgin/s pflt/s vflt/s slock/s 14:20:00 32.36 0.81 0.12 0.00 0.00 0.67 0.58 0.00 14:40:00 16.80 0.68 0.13 0.01 0.01 0.53 0.58 0.00 15:00:36 25283.5 22608.44 868.78 73.13 755.70 3.60 21694.5 0.00 15:20:17 50990.9 47237.77 1213.85 102.90 1024.64 2.11 46300.0 0.00 15:40:21 49062.2 45470.76 959.30 107.34 1043.16 2.50 44531.3 0.00 16:01:34 9258.46 5785.47 1208.09 100.80 1058.63 1.99 4750.43 0.00 16:20:05 5029.81 1167.18 1202.24 106.10 1129.21 2.05 14.72 0.00 16:40:05 3883.06 1068.23 1197.67 107.10 1102.29 2.21 20.00 0.00 17:00:00 1658.82 309.02 356.65 34.28 315.99 1.37 13.99 0.00 17:20:00 19.74 1.07 0.23 0.08 0.19 0.68 1.07 0.00 Average 4221.61 3049.32 178.50 15.97 156.31 286.69 3368.84 0.00
atch/s
| Page faults per second that are satisfied by reclaiming a page currently in memory (attaches per second). |
atfree/s
| Page faults per second that are satisfied by a page on the free list. |
atmiss/s
| Page faults per second not fulfilled by a page in memory. |
pgin/s
| Page-in requests per second. |
ppgin/s
| Pages paged-in per second. |
pflt/s
| Page faults from protection errors per second (invalid access to page or ``copy-on-writes''). |
vflt/s
| Address translation page faults per second (valid page not in memory). The number of valid pages referenced per second that were not found in physical memory. A referenced page that was previously paged out to swap, or exists as a text or data page in the filesystem is loaded from disk. |
slock/s
| Faults per second caused by software lock requests requiring physical I/O. |
If the system is found to be memory bound there are a number of things that can be done. The most obvious and that which will probably bring the most benefit is to add more physical memory to your system and retune it. If this is not possible then a number of alternatives exist:
SZ value gives the virtual memory
(swappable) size of the process's
stack and data (both initialized and uninitialized)
regions
in 1KB units.
If many memory
intensive processes are being run simultaneously then
rescheduling these
jobs
to run at alternative times will redistribute the use of memory.
To see if any memory-intensive
jobs running at peak times can be rescheduled,
you should also check the system's
crontab(C)
files.
It is also possible that some applications programs may have a memory leak and are continuously increasing their size in virtual memory. If you suspect that an application has a memory leak, you should restart the program before its usage of virtual memory starts to make the system swap or page out. You may notice this problem with server processes that run continuously for several weeks.
You should also ensure that the applications do not have a memory leak.
If sar -b
shows that the %rcache and %wcache hit rates are
consistently high, memory may be regained for use by user processes
by reducing the size of the buffer cache.
(See
``How the buffer cache works''
for a description of its operation.)
It is not possible to recommend minimum values for the read and write hit rates. It depends on the amount of extra disk I/O that will be generated and the performance characteristics of the system's disks. Reducing the buffer cache hit rates also means that more processes have to wait for I/O to complete. This increases the total time that processes take to execute and it also increases the amount of context switching on the system.
You may, for example, decide that you can tolerate reducing
current hit rate values of %rcache from 95% to 90%
and %wcache from 65% to 60% provided that your
system's disks can cope with the increased demand and also
that any deterioration in the performance of applications is
not noticeable.
See ``Buffer cache parameters'' for how to reduce the kernel's buffer chace requirements.
On previous releases, you could specify the size of various static data structures in the kernel such as the process, in-core inode, open file, and lock tables. On SCO OpenServer and most other modern UNIX systems, the operating system dynamically allocates memory to system tables. In this way, they grow over time to accommodate maximum demand. System table usage can be seen with sar -v
14:00:00 proc-sz fail lwp fail inod-sz fail file fail lock 14:20:00 80/5426 0 169 0 5/50500 0 475 0 4 14:40:00 80/5426 0 169 0 5/50500 0 475 0 4 15:00:36 100/5426 0 235 0 5607/50500 0 545 0 4 15:20:17 101/5426 0 236 0 5462/50500 0 525 0 4 15:40:21 95/5426 0 230 0 5/50500 0 549 0 4 16:01:34 101/5426 0 236 0 5615/50500 0 549 0 4 16:20:05 97/5426 0 232 0 5563/50500 0 556 0 4 16:40:05 98/5426 0 233 0 5652/50500 0 560 0 4 17:00:00 83/5426 0 222 0 5657/50500 0 512 0 4 17:20:00 80/5426 0 219 0 5641/50500 0 488 0 4 Average 84/5426 0 204 0 3670/50500 0 504 0 3
proc-sz
| used and grown size of the process table |
lwp
| used and grown size of the LWP table |
inod-sz
| used and grown size of the inode table |
file
| used and grown size of the file table |
lock
| used and grown size of the lock table |
fail
| number of times an entry could not be allocated in a table |
Only the size of the lock table can be specified via a kernel tunable. FLCKREC, which has a maximum value of 65534.
If your SCO OpenServer system is short of memory, you can release memory for use by simplifying the Desktop environment.
If your system is very memory bound, consider making the following changes. These are given in order, from the most to the least effective in releasing memory for use:
The SCO X server supported in previous releases is replaced in OSR6 by the X.org X server. The scologin(XC) display manager starts an X.org X server using the options specified in the file /usr/lib/X11/scologin/Xservers.
The X server's environment variables and command line options are discussed on the and manual pages. Among the server options that affect performance:
Although the following kernel parameters do not directly affect performance, they are important for the correct operation of the X Window System, the Desktop, and X terminals. You may be unable to start an X client if you do not enough of these resources configured. See Configuring Kernel Parameters for details of how to change the value of kernel parameters.
Input/output (I/O) is the process of transferring data from memory to a device, from a device to memory, or from one device to another. Most I/O usually occurs between memory and the system's hard disk drives, and between the system and various peripheral devies (such as terminals, printers, etc.).
If the speed at which peripheral devices can access and communicate data to the system is relatively slow, the operating system may spend most of its time idle waiting for I/O with many processes asleep until the I/O completes.
The following sections contain information about the monitoring and tuning of various I/O subsystems:
There are two methods of transferring data between memory and disk:
AIO is supported by the AIO library functions in Section AIO. These are similar to the POSIX AIO functions provided in previous releases. Note that the aio(HW) driver and associated commands (aioinfo and aiolkinit) present in previous releases are no longer supported. See ``Asynchronous I/O'' in Programming with System Calls and Libraries for more information.
Synchronous I/O operations to the raw disk device force the process requesting the operation to wait for it to complete. Database applications typically use synchronous I/O to ensure the integrity of the data being written to disk. For example, the journal logs that a database uses to recover in the event of system failure are written to disk using synchronous I/O.
To make the transfer of data between memory and disk more efficient, the system maintains a buffer cache of most recently accessed disk data. This reduces the amount of disk I/O that the system needs to perform. See ``How the buffer cache works'' for a description of its operation.
In a similar way, the system maintains a directory name lookup cache (DNLC) of most recently used filenames in order to speed up locating files within filesystems. (This replaces the namei cache used on earlier systems.) See ``How the DNLC works'' for a description of its operation and tuning recommendations.
For a description of how to monitor the activity of block devices including disks, see ``Viewing disk and other block I/O activity''.
Disk I/O and networked filesystem (such as NFS®) performance are affected by filesystem fragmentation and other filesystem-related factors as described in ``Filesystem factors affecting disk performance''.
On a typical system, performance can be improved by efficient use of the buffer cache, depending on the mix of jobs running.
The buffer cache is used by the kernel to hold filesystem metadata, such as inodes, indirect blocks, and cylinder groups. The buffer cache is created in an area of kernel memory and is never swapped out. Although the buffer cache can be regarded as a memory resource, it is primarily an I/O resource due to its use in mediating data transfer.
When a user process issues a read request, the operating system searches the buffer cache for the requested data. If the data is in the buffer cache, the request is satisfied without accessing the physical device. It is quite likely that data to be read is already in the buffer cache because the kernel copies an entire block containing the data from disk into memory. This allows any subsequent data falling within that block to be read more quickly from the cache in memory, rather than having to re-access the disk. The kernel also performs read-ahead of blocks on the assumption that most files are accessed from beginning to end.
If data is written to the disk, the kernel first checks the buffer cache to see if the block, containing the data address to be written, is already in memory. If it is, then the block found in the buffer cache is updated; if not, the block must first be read into the buffer cache to allow the existing data to be overwritten.
When the kernel writes data to a buffer, it marks it as delayed-write. This means that the buffer must be written to disk before the buffer can be re-used. Writing data to the buffer cache allows multiple updates to occur in memory rather than having to access the disk each time. Once a buffer has aged in memory for a set interval it is written to disk.
The kernel parameter NAUTOUP specifies how long a delayed-write buffer can remain in the buffer cache before its contents are written to disk. The default value for NAUTOUP is 60 seconds, and ranges between 0 and 1200 (20 minutes). It does not cause a buffer to be written precisely at NAUTOUP seconds, but at the next buffer flushing following this time interval.
Although the system buffer cache significantly improves overall system throughput, in the event of a system power failure or a kernel panic, data remaining in the buffer cache but which has not been written to disk may be lost. This is because data scheduled to be written to a physical device will have been erased from physical memory (which is volatile) as a consequence of the crash.
The default interval for writing aged buffers to disk (also called flushing the buffer) is 1 second. The kernel parameter FDFLUSHR (BDFLUSHR in previous releases) controls the flushing interval. You can configure FDFLUSHR to take a value in the range 1 to 1200 seconds.
If your system crashes, you will lose NAUTOUP + (FDFLUSHR/2) seconds of data on average. With the default values of these parameters, this corresponds to 60.5 seconds of data. Decreasing FDFLUSHR will increase data integrity but increase system overhead. The converse is true if you increase the interval.
Apart from adjusting the aging and flushing intervals, you can also control the size of the buffer cache. The kernel parameter BUFHWM (NBUF in previous releases) determines the amount of memory in kilobytes that is available for buffers. The default value is autotuned based on the amount of physical and kernel virtual memory configured.
The amount of memory reserved automatically for buffers may be not be optimal depending on the mix of applications that a system will run. For example, you may need to increase the buffer cache size on a networked file server to make disk I/O more efficient and increase throughput. You might also find that reducing the buffer cache size on the clients of the file server may be possible since the applications that they are running tend to access a small number of files. It is usually beneficial to do this because it increases the amount of physical memory available for user processes.
How you can investigate the effectiveness of the buffer cache is the subject of ``Viewing buffer cache activity''.
For more information on tuning the size of the buffer cache see ``Buffer cache parameters''.
Buffer cache activity can be seen using sar -b (or mpsar -b for SMP):
14:00:00 bread/s lread/s %rcache bwrit/s lwrit/s %wcache pread/s pwrite/s 14:20:00 0 15 100 1 2 47 0 0 14:40:00 0 14 100 1 1 48 0 0 15:00:36 0 705 100 3 7 57 0 0 15:20:17 0 1340 100 4 9 58 0 0 15:40:21 0 1316 100 4 8 55 0 0 16:01:34 0 186 100 3 8 62 0 0 16:20:05 0 39 100 3 8 64 0 0 16:40:05 0 38 100 3 7 64 0 0 17:00:00 0 25 100 2 4 55 0 0 17:20:00 0 14 100 1 1 50 0 0 Average 0 301 100 2 3 42 0 0The buffer cache read hit rate,
%rcache, indicates the percentage by volume of data
read from disk (or any block device) where the data was already
in the buffer cache.
This number should be consistently above 90%.
The buffer cache write hit rate,
%wcache, indicates the percentage by volume of data written to
disk (or any block device) where the block in which the data was to be
written was already in the buffer cache.
This number should be consistently above 60%.
%rcache and
%wcache are also equal to the percentage of read and write
requests satisfied using the buffer cache.
If %rcache is below 90% or %wcache is below 60%,
then you will probably see performance gains by increasing the size of
the buffer cache.
bread/s indicates the average
number of kilobytes per second read from the
block devices (including disk drives) into the
the buffer cache.
bwrit/s indicates the average number of kilobytes
per second written from the buffer cache to block devices (e.g.,
when the buffers are flushed).
If the read and write buffer cache hit rates
(%rcache and %wcache) reported by
sar -b show consistently low values
(less than 90% for read and less than 60% for write),
you can improve disk I/O performance by
increasing the size of the buffer cache.
This is particularly worth doing if the number of kilobytes
of data transferred per second between the buffer cache and disk
(bread/s + bwrit/s) is high.
You can also examine the
benefit to disk I/O performance
using sar -d as described in
``Viewing disk and other block I/O activity''.
This should show improved
%busy, avque, and avwait
figures for disks containing regularly accessed filesystems
as the buffer cache size is increased.
Even if the impact on disk I/O is not significant,
requesting processes benefit by not having to perform as many
waits because of cache misses.
You should also note that increasing the size of the buffer cache directly reduces the amount of memory available for user processes. If free memory is reduced, the system may be more susceptible to paging out and swapping. If you increase the buffer cache size, you should monitor paging and swapping as well as buffer cache activity.
See ``Tuning Memory Resources'' for information on monitoring paging and swapping.
If a compromise cannot be reached between these resources and the applications being run cannot be tuned to reduce disk access, then the only alternative are to add more memory or improve the throughput of the disk drives.
To increase the size of the buffer cache, increase the values of BUFHWM, NBUF, NHBUF and NPBUF as discussed under ``Buffer cache parameters''.
While a general recommendation of 90% for %rcache and 60%
for %wcache is appropriate for many systems, the values
depend to a great extent on the mix of applications that your system is
running, the speed of its disk subsystems, and on the amount of
memory available.
The maximum possible value of %rcache depends on how
often new files are accessed whose data has not already been
cached. Applications which read files sporadically or randomly
will tend to have lower values for %rcache.
If files are read which are not then subsequently re-read,
this has the additional disadvantage of removing possibly useful
buffers from the cache for reading and writing.
The effectiveness of caching blocks for write operations depends on how often applications need to modify data within the same blocks and how long delated-write buffers can remain in the buffer cache before their contents are written to disk. The average time that data remains in memory before being flushed is NAUTOUP + (FDFLUSHR / 2). This is 60.5 seconds given the default values of these parameters.
If applications tend to write to the same blocks on a time scale that is greater than this, the same buffers will be flushed to disk more often. If applications append to files but do not modify existing buffers, the write hit rate will be low and the newly written blocks will tend to remove possibly useful buffers from the cache. If you are running such applications on your system, increasing the buffer cache size may adversely affect system performance whenever the buffer flushing daemon runs. When this happens, applications may appear to stop working temporarily (hang) although most keyboard input will continue to be echoed to the screen. Applications such as vi(C) and telnet(TC) which process keyboard input in user mode may appear to stop accepting key strokes. The kernel suspends the activity of all user processes until the flushing daemon has written the delayed-write buffers to disk. On a large buffer cache, this could take several seconds. To improve this situation, spread out the disk activity over time in the following ways:
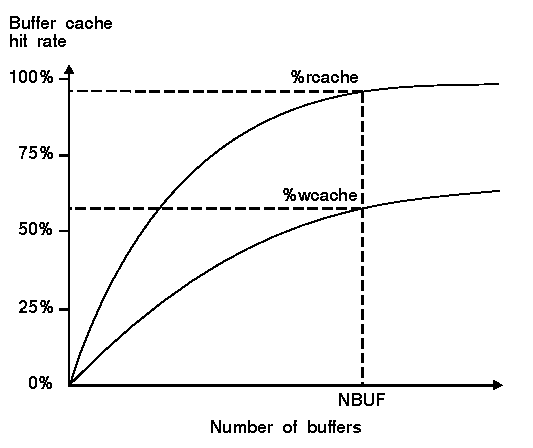
Buffer cache hit rates
The figure above shows how the buffer cache read and write hit rates might increase as the number of buffers is increased. There are several points to notice here:
%rcache and %wcache).
If the number of kilobytes of data read per second into the buffer
cache from disk (bread/s) is much higher than
the number written to disk (bwrit/s), you should
attach more significance to the value of %rcache.
On most systems, you will find that there is more data read
from than written to disk.
If the amount of free memory drops drastically and the system begins to page out and swap, you should reduce the size of the buffer cache. See ``Tuning Memory Resources'' for more information.
In order to find a file referenced by a given pathname, each
of the components of the pathname must be read to find the
subsequent component. For example, take the file /etc/passwd
when used in a command such as:
cat /etc/passwd
In order to find the file passwd, the root directory (/) must first be found on the disk. Then the entry for the pathname component etc is used to locate that directory. The etc directory is read from the disk and used to locate the file passwd. The file passwd can then be read from the disk.
All of the above steps use Index Nodes or inodes. A file in a filesystem is represented by an inode which records its type, size, permissions, location, ownership, and access and modification dates. To locate the file's data, the inode also stores the block number (or numbers) of the disk blocks containing the data. Note that the inode does not contain the name of the file. Another file, a directory, stores the filename together with the corresponding inode number. In this way, several directory entries (or filenames) may refer to the same inode; these are known as hard links.
When a command accesses a pathname, such as /etc/passwd, the process of translating name to inode to data block has to be carried out for every component of the pathname before the file's data can be located. If a pathname component is a directory, such as /etc, the data blocks pointed to by its inode contain a map of filenames to inodes. This map is searched for the next pathname component, and this process continues until the final name component is reached. All inodes can be looked up in the inode table stored in memory, or if not present there, at the head of the filesystem on disk where a linear list of inodes is kept. The in-core inode table stores additional information so that the kernel accesses the correct device if more than one filesystem exists.
Converting pathnames to inode numbers is a time-consuming process. It may require several disk accesses to read the inodes corresponding to the components of a directory pathname. The DNLC is used to reduce the number of times the disk must be accessed to find a file. When a command wishes to open a file, the kernel first looks in the DNLC for each pathname component in turn. If it cannot find a component there, it retrieves the directory information from disk into the buffer cache and adds the entry to the namei cache if possible.
The effectiveness of the system's DNLC can be seen using sar -a:
14:00:00 iget/s namei/s dirbk/s %dnlc 14:20:00 6 124 13 97 14:40:00 6 124 12 97 15:00:36 9 810 693 83 15:20:17 6 1443 1326 82 15:40:21 6 1422 1304 82 16:01:34 6 288 174 88 16:20:05 6 143 27 96 16:40:05 6 145 27 96 17:00:00 7 133 19 96 Average 6 516 401 84
| iget/s | number of files located by inode entry |
| namei/s | number of filesystem path searches |
| dirbk/s | number of directory block reads issued |
| %dnlc | hit rate of directory name lookup cache |
The size of the DNLC is determined by the DNLCSIZE kernel tunable
parameter, which is autotuned by the kernel depending on the size of
physical and kernel virtual memory.
The value of DNLCSIZE is determined by this formula:
800 + (<physical memory in MB> - 16) * 12.5
In practice, the kernel limits the autotuned value of DNLCSIZE to 13400, but this can be tuned to a larger value manually.
The activity of block devices installed on the system, including floptical, floppy and hard disk drives, CD-ROM and SCSI tape drives, can be examined using sar -d (or mpsar -d for SMP). This example shows the activity for a single SCSI disk:
14:00:00 device MB %busy avque r+w/s blks/s avwait avserv 14:20:00 c0b0t0d0p2s2 13766 0 4.6 1 12 0.7 0.2 14:20:00 c0b0t0d0p2 29314 0 4.6 1 12 0.7 0.214:40:00 c0b0t0d0p2s2 13766 0 5.3 1 12 0.8 0.2 14:40:00 c0b0t0d0p2 29314 0 5.3 1 12 0.8 0.2
15:00:36 c0b0t0d0p2s1 838 46 5.7 4 198 525.1 112.8 15:00:36 c0b0t0d0p2s2 13766 69 21.2 126 12746 110.8 5.5 15:00:36 c0b0t0d0p2 29314 69 24.9 131 12945 127.5 5.3
15:20:17 c0b0t0d0p2s1 838 88 4.0 8 234 316.0 104.1 15:20:17 c0b0t0d0p2s2 13766 99 23.2 174 17486 126.3 5.7 15:20:17 c0b0t0d0p2 29314 99 26.7 182 17720 139.9 5.4
15:40:21 c0b0t0d0p2s1 838 90 4.9 10 231 337.8 87.0 15:40:21 c0b0t0d0p2s2 13766 99 23.5 160 15578 139.3 6.2 15:40:21 c0b0t0d0p2 29314 99 27.9 171 15809 156.7 5.8
16:01:34 c0b0t0d0p2s1 838 95 3.6 5 272 415.9 160.3 16:01:34 c0b0t0d0p2s2 13766 100 23.1 173 17768 127.2 5.7 16:01:34 c0b0t0d0p2 29314 100 26.5 179 18041 142.0 5.6
16:20:05 c0b0t0d0p2s1 838 96 1.5 5 71 84.2 186.0 16:20:05 c0b0t0d0p2s2 13766 99 21.0 178 18245 112.1 5.6 16:20:05 c0b0t0d0p2 29314 99 22.4 183 18317 116.6 5.4
16:40:05 c0b0t0d0p2s1 838 97 1.2 9 108 21.0 106.7 16:40:05 c0b0t0d0p2s2 13766 99 18.3 174 17932 99.4 5.7 16:40:05 c0b0t0d0p2 29314 99 19.5 183 18040 100.8 5.4
17:00:00 c0b0t0d0p2s1 838 31 2.2 4 83 84.8 70.5 17:00:00 c0b0t0d0p2s2 13766 32 22.6 54 5239 127.9 5.9 17:00:00 c0b0t0d0p2 29314 32 24.6 58 5323 130.0 5.5
Average c0b0t0d0p2s1 838 60 3.2 5 134 250.9 114.1 Average c0b0t0d0p2s2 13766 66 21.8 116 3703 119.6 5.7 Average c0b0t0d0p2 29314 66 24.7 121 3838 130.3 5.5
device shows the name of the device whose activity is
being reported. In this example, the devices are the first and second
slices of the second partition on the primary hard disk (c0b0t0d0p2s1,
c0b0t0d0p2s2) and the entire primary hard disk (c0b0t0d0p2).
MB lists the size in megabytes of the disk or slice.
%busy indicates the percentage of time
that the system was transferring data to and from the device.
avque indicates the average
number of requests pending on the device including
any on the device itself.
This number is usually greater than the
number of processes waiting to access the device
if scatter-gather read ahead is being performed
on behalf of a filesystem.
avwait represents the average time in milliseconds
that the request waits in the driver before being sent to the device.
avserv represents the average time in milliseconds
that it takes a request to complete.
The length of time is calculated from the time that the
request was sent to the device to the moment that the
device signals that it has completed the request.
Note that avserv values vary considerably
according to the type of disk and any caching on the disk
controller.
r+w/s is the number of read and write
transfers from and to the disk, and
blks/s is the number of 512-byte blocks
transferred per second. These two values can be used
to calculate the average size of data transfers
using the formula:
Average size of data transfer = blks/s / r+w/s
A system is
I/O bound,
or has an I/O
bottleneck,
if the peripheral devices (hard disk, tape, and so
on) cannot transfer data as fast as
the system requests it.
This causes processes to be put to sleep,
``waiting for I/O'', and leaves
the CPU(s) idle for much of the time.
To determine
if the system is disk I/O bound run sar -u
and look at the %wio value.
This displays the percentage of time that each CPU
spends waiting for I/O to complete while there are
no
runnable processes.
If this value is high
then it is possible that I/O is not keeping up with
the rest of the system.
(You should not always assume that
there is a problem with disks; for example,
%wio might be high because a tape drive is
being accessed.)
Other indications of a disk I/O
bottleneck can be seen using sar -d,
Note that sar -d can be also be used to view the
activity of block I/O devices including
hard disk drives, SCSI tape drives, and floppy disks.
If the values for %busy and avque are both
consistently high then the devices cannot keep up with the requests to
transfer data.
Devices such as floppy disks and some older types of tape drive are
inherently slow.
As these devices are generally infrequently used -- for
system backup, software installation, and so on -- there is
little that performance tuning can usefully accomplish.
The value of blks/s
displayed by sar -d
can be combined with %busy to give an
indication of the maximum I/O
throughput of a disk, and
may suggest where a I/O bottleneck can occur:
Maximum disk throughput (KB/s) = blks/s  50 /
50 / %busy
High values of the ratio of avwait to avserv
also suggest that the device is saturated with requests.
If the number of transfers, r+w/s,
is high but the amount of data being transferred,
blks/s, is low, it may be possible to
modify the application to transfer larger amounts of data
less frequently. This should reduce the number of requests
for the disk and reduce contention for it.
The read and write hit rates (%rcache and
%wcache) shown by sar -b should
show high values.
If these values fall, the system is having to access blocks
on disk (or other block devices) rather than in the
buffer cache.
If this happens, increasing the size of the buffer cache
may help to alleviate a disk I/O bottleneck.
A low hit rate for the Directory Name Lookup Cache (DNLC)
could lead to the disk
being accessed more often in order to convert pathname components
to inode numbers.
If sar -n displays results showing that
hit % is consistently low
then the DNLC cache for the corresponding filesystem type
is too small. It is not possible to give
a general definition of what is a low value since this
depends on the application mix that you run on your system.
Because the performance of the DNLC cache does not depend linearly
on its size, you will find that improving cache hit
rates that are already high requires a significantly greater
cache size.
If the system is I/O bound because of disk activity, there are a number of things that can be done:
You may find that the performance of the system can be improved slightly by increasing the values of the FDFLUSHR and NAUTOUP kernel parameters. This will reduce the number of times the disk will be accessed because blocks can be updated more often in memory before they are written to the disk. The inherent risk is that more data will be lost if the system crashes because it will be longer since it was last written to the disk. It is considered good practice to protect mission-critical systems against power failure using a UPS or similar device.
Various disk organization strategies are discussed in ``Overcoming performance limitations of hard disks'' which includes suggestions for optimizing your current hardware configuration.
Disk manufacturers implement various hardware and firmware (software in the disk controller) strategies to improve disk performance. These include track caching and varying the number of disk blocks per track across the disk surface. Usually, you have no control over such features.
In previous releases, the SCSI disk driver maintained a queue of disk requests to be sent to the disk controller. This is no longer supported and the sar command no longer supports the -S option to report SCSI request block usage.
Traditional UNIX filesystems use inodes to reference file data held in disk blocks. As files are added and deleted from the filesystem over time, it becomes increasingly unlikely that a file can be allocated a contiguous number of blocks on the disk. This is especially true if a file grows slowly over time as blocks following its present last block will probably become allocated to other files. To read such a file may require many head seek movements and consequently take a much longer time time than if its blocks were written one after another on the disk.
AFS, EAFS, and HTFS filesystems try to allocate disk blocks to files in clusters to overcome fragmentation of the filesystem. Fragmentation becomes more serious as the number of unallocated (free) disk blocks decreases. Filesystems that are more than 90% full are almost certainly fragmented. To defragment a filesystem archive its contents to tape or a spare disk, delete the filesystem and then restore it.
On inode-based filesystems, large files are represented using single, double, and even triple indirection. In single indirection, a filesystem block referenced by an inode holds references to other blocks that contain data. In double and triple indirection, there are respectively one and two intermediate levels of indirect blocks containing references to further blocks. A file that is larger than 10 filesystem blocks (10KB) requires several disk operations to update its inode structure, indirect blocks, and data blocks.
Directories are searched as lists so that the average time to find a directory entry initially increases in direct proportion to the total number of entries. The blocks that a directory uses to store its entries are referenced from its inode. Searching for a directory entry therefore becomes slower when indirect blocks have to be accessed. The first 10 direct data blocks can hold 640 14-character filename entries. The Directory Name Lookup Cache (DNLC) can overcome some of the overhead that would result from searching large directories. It does this by providing efficient translation of name to inode number for commonly-accessed pathname components.
You can increase the performance of HTFS filesystems by disabling checkpointing and transaction intent logging. To do this for an HTFS root filesystem, use the Hardware/Kernel Manager or configure(ADM) to set the values of the kernel parameters ROOTCHKPT and ROOTLOG to 0. Then relink the kernel and reboot the system. For other HTFS filesystems, use the Filesystem Manager to specify no logging and no checkpointing or use the -onolog,nochkpt option modifiers with mount(ADM). The disadvantage of disabling checkpointing and logging is that it makes the filesystem metadata more susceptible to being corrupted and potentially unrecoverable in the case of a system crash. Full filesystem checking using fsck(ADM) will also take considerably longer.
For more information on these subjects see ``Maintaining filesystem efficiency'' and ``How the DNLC works''.
The performance of VXFS filesystems is discussed in the VXFS System Administrator's Guide, under Performance and Tuning. Note that the majority of VXFS filesystem tunables are configured using the vxtunefs(ADM) command. There is only one tunable for VXFS that is managed with configure/idtune; see ``VXFS filesystem parameters''.
One area where you are likely to experience performance limitations is with I/O from and to hard disks. These are heavily used on most systems, and accessing data on them is much slower than is the case with main memory. The time taken to access main memory is typically many thousands of times less than that taken to access data on disk. The solution is to try to arrange for the data that you want to be in a memory cache when you need it, not on disk. The cache may be one maintained by the operating system, though many applications such as databases manage their own caching strategies in user space. The situation is helped further by modern disks and disk controllers which implement cache memory in hardware.
``Increasing disk I/O throughput by increasing the buffer cache size'' describes how you can tune the buffer caching provided for access through the interface to block devices such as hard disks.
``Viewing DNLC activity'' describes how to tune the DNLC cache. This is the cache that the system maintains to avoid disk access when mapping filenames to inode numbers.
Not all activity on disk involves access to filesystems. Examples are swapping and paging to swap space, and the use of raw disk partitions by many database management systems. It is worth examining disk transfer request activity to discover how busy a system's disks are at the lowest level. ``Viewing disk and other block I/O activity'' describes how you can monitor the activity of block I/O in a system not only for block-structured media such as hard disk, CD-ROM, floppy and floptical disks, but also for SCSI tape drives.
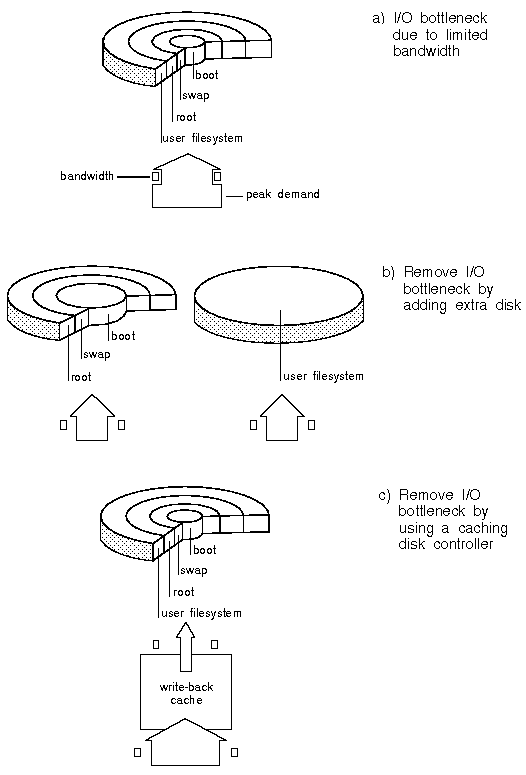
Curing a disk I/O bottleneck caused by limited bandwidth
Comparison of I/O activity allows you to see if activity between different disks is unbalanced. In itself, this is not a problem unless the bandwidth of a particular disk is limiting throughput. ``Curing a disk I/O bottleneck caused by limited bandwidth'' shows a system where a disk I/O bottleneck is cured by the addition of an extra disk or a caching disk controller. Adding an extra disk is likely to be successful unless the bandwidth limitation occurs elsewhere, for example, in the disk controller. Adding a caching controller is likely to succeed where a disk is having difficulty coping with peak demand. A write-back cache should be backed up by a UPS to guard against mains power failure and the consequent data loss that would occur.
Balancing activity between disks may sometimes be achieved by simply moving a filesystem between two disks. A disk I/O bottleneck may occur if applications software and a user filesystem coexist on the same disk. This may lead to large access times as the disk heads are consistently sweeping across the entire disk. One solution is to move the applications software to other disk(s). The documentation for the applications may provide guidelines for this.
It is often unwise to move software or user filesystems onto the hard disk containing the root filesystem. Depending on how you use the system, this can be one of the most heavily-used disks.
A common source of disk bottlenecks on relational database servers occurs when the journal logs (used if the system has to recover from a crash) share the same disk as database tables and indexes. The journal logs are constantly updated and the disks containing them are usually the busiest on the system. The journal logs are also written sequentially so keeping them on separate disks reduces seek time. ``Curing a disk I/O bottleneck caused by unbalanced disk I/O activity'' shows how a disk dedicated for use by the journal logs might be added to a system in order to remove a bottleneck.
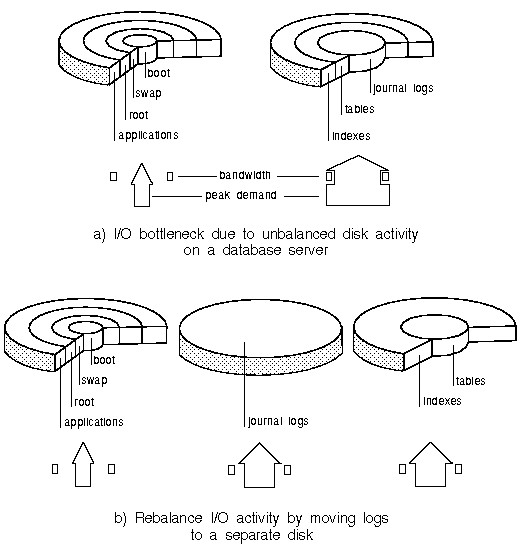
Curing a disk I/O bottleneck caused by unbalanced disk I/O activity
The clist mechanism used in previous releases to buffer TTY input over serial lines is no longer supported, as are the NCLIST and TTHOG tunable patrameters. See Terminal Device Control for an overview of serial line processing, including improving performance.
Note that no special configuration is needed for high-speed modems on serial lines, as was required in previous releases.
Networking protocol stacks and the programs which run over them place additional burdens on your system's resources, including CPU and memory. This chapter describes the areas of concern for the network administrator, the tools used to diagnose performance problems, and procedures used to enhance network performance for STREAMS, TCP/IP, and NFS:
See also:
The X Window System, networking services such as TCP/IP and NFS, applications that use streams pipes, and certain device drivers use STREAMS to perform I/O.
The STREAMS I/O system was designed to provide a simultaneous two-way (full duplex) connection between a process running in user space and a device driver (or pseudo-device driver) linked into the kernel. The topmost level within the kernel with which the user process communicates is known as the stream head.
Using STREAMS has the advantage that it allows the processing of I/O between an application and a device driver to be divided into a number of functionally distinct layers such as those required by network architectures that implement TCP/IP or the Open Systems Interconnection (OSI) 7-layer model.
The STREAMS I/O mechanism is based on the flow of messages from the stream head to a device driver, and in the opposite direction, from the device driver to the stream head. Messages that are passed away from the stream head toward the driver are said to be traveling downstream; messages going in the opposite direction are traveling upstream. Between the stream head and the driver, there may be a number of stream modules which process messages in addition to passing them to the next module. Each type of module is implemented as a separate driver linked into the kernel. For example, the udp driver implements the network module that applies the UDP protocol to messages. Each module has two separate queues for processing upstream and downstream-bound messages before handing them to the next module.
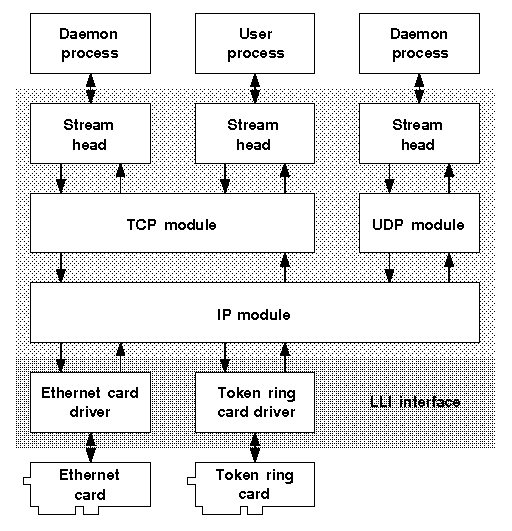
Implementation of networking protocols using STREAMS
A network protocol stack is built by linking STREAMS protocol modules. For example, the TCP/IP protocol stack is built by linking the Internet Protocol (IP) module, and the Transmission Control Protocol (TCP) module. Modules can also be multiplexed so that a module can talk to several stream heads, drivers or other modules. ``Implementation of networking protocols using STREAMS'' shows:
For a more complete picture of the available protocol stacks and drivers, see ``Network hardware drivers''.
``Creating an Ethernet frame by successive encapsulation'' shows how the TCP/IP protocol stack encapsulates data from an application to be sent over a network that uses Ethernet as the physical layer. The Transport layer module adds a header to the data to convert it into a TCP segment or a UDP packet. The Internet layer module turns this into an IP datagram, and then passes it to the network driver which adds a header and CRC trailer. The resulting Ethernet frame is then ready for transmission over the physical medium.
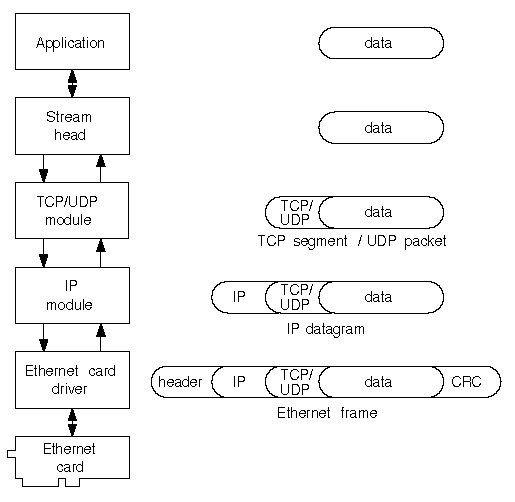
Creating an Ethernet frame by successive encapsulation
To retrieve data from an Ethernet frame, the inverse process is applied; the received information is passed as a message upstream where it is processed by successive modules until its data is passed to the application. If the information is received by a router between two networks, the message will only travel upward as far as the Internet layer module from one network adapter before being passed back down to a different network adapter.
``Virtual and physical connections over a network'' shows protocol stacks on two machines linked via a physical connection technology such as Ethernet, Token Ring or Fiber Distributed Data Interface (FDDI). Applications appear to have a direct or virtual connection; they do not need to know how connection is established at the lower levels.
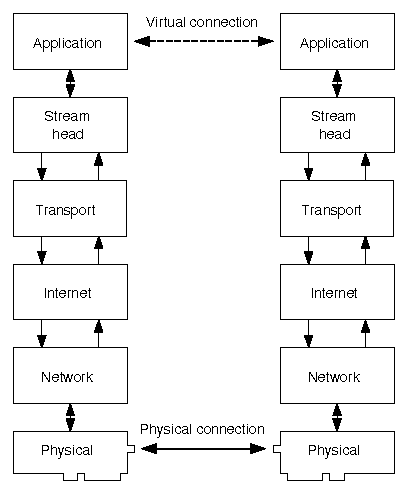
Virtual and physical connections over a network
The primary usage of memory by the STREAMS subsystem is for building messages. ``Memory structures used by STREAMS messages'' illustrates how a message is created from pieces dynamically allocated from the memory reserved for use by STREAMS. Each message consists of a fixed-size message header and one or more buffer headers attached to buffers. The buffers come in several different sizes and contain the substance of the message such as data, ioctl control commands (see ioctl(S), and streamio(M)), acknowledgements, and errors.
Message buffers are available in 15 sizes or classes:
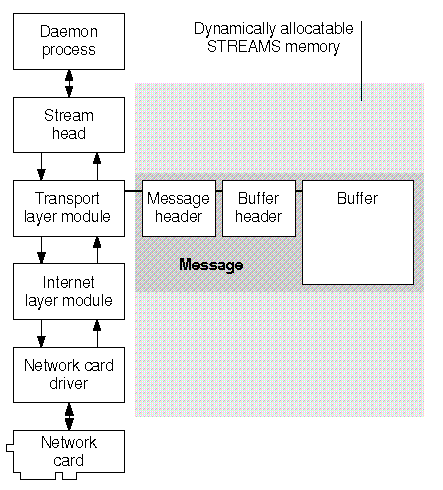
Memory structures used by STREAMS messages
Four kernel parameters are important for the configuration of STREAMS: NSTRPAGES, STRSPLITFRAC, NSTREAM, and STRMAXBLK.
NSTRPAGES controls the total amount of physical memory that can be made available for messages. The kernel can dynamically allocate up to NSTRPAGES pages of memory for message headers, buffer headers, and buffers. If a message needs a buffer which is not currently available on the free list of buffers, a new buffer is dynamically allocated for use from memory. If more than STRSPLITFRAC percent of NSTRPAGES is in use and a suitable buffer is not available on the free list, the kernel will try to split a larger buffer for use and only allocates more memory if this fails.
The default value of STRSPLITFRAC is 80%; if you set this value lower, STREAMS will use less memory which will tend to become fragmented more quickly. When this happens, unallocated STREAMS memory exists as many small non-contiguous pieces which are unusable for large buffers. The STREAMS daemon, strd, manages memory on behalf of the STREAMS subsystem. If strd runs, it expends CPU time in system mode in order to release pages of STREAMS memory for use (this is known as garbage collection).
NSTREAM controls the number of stream heads that can be used. One stream head is needed for each application running on your machine that uses STREAMS to establish connections. Applications that use stream pipes require two stream heads per pipe.
Examples of applications that use stream heads are:
NOTICE: program: out of streamsIf you see such a message, increase the value of NSTREAM, relink the kernel, and reboot.
Each configured stream head requires 80 bytes of memory. Apart from this overhead, the value of NSTREAM has no effect on performance.
STRMAXBLK controls the maximum size of a STREAMS message buffer. You must adjust the value of this parameter to 4096 if you are using older network cards whose LLI drivers use programmed DMA to transfer data directly between the interface card and memory. These drivers assume that the 4KB memory pages that compose a buffer are contiguous in physical memory. As STREAMS use dynamically allocated memory, this may not be the case. To avoid memory being corrupted, the maximum message buffer size must be set equal to the size of a memory page.
See also:
Your SCO OpenServer system uses the STREAMS mechanism to support TCP/IP and other network protocols. such as . You should ensure that you provide an appropriate number of STREAMS resources for TCP/IP; without them, performance may suffer or the system may hang.
Run the netstat -m command to display STREAMS memory usage:
streams allocation:
config alloc free total max fail
streams 160 84 76 215 87 0
queues 452 394 58 496 414 0
mblks 271 102 169 49326 183 0
buffer headers 442 391 51 5964 395 0
class 1, 64 bytes 64 0 64 20289 44 0
class 2, 128 bytes 96 0 96 8668 72 0
class 3, 256 bytes 64 7 57 7174 63 0
class 4, 512 bytes 32 8 24 1334 25 0
class 5, 1024 bytes 4 0 4 904 3 0
class 6, 2048 bytes 104 62 42 622 103 0
class 7, 4096 bytes 8 8 0 93 8 0
class 8, 8192 bytes 1 0 1 13 1 0
class 9, 16384 bytes 1 0 1 1 1 0
class 10, 32768 bytes 0 0 0 0 0 0
class 11, 65536 bytes 0 0 0 0 0 0
class 12, 131072 bytes 0 0 0 0 0 0
class 13, 262144 bytes 0 0 0 0 0 0
class 14, 524288 bytes 0 0 0 0 0 0
total configured streams memory: 2000.00KB
streams memory in use: 185.98KB
maximum streams memory used: 334.43KB
For each data structure used, the important column is the fail
column shown by netstat -m.
If this is non-zero for the number of stream heads configured
(shown as the value in the row labeled streams under
the config column), increase the value of NSTREAM using
configure(ADM)
as described in
UNRESOLVED XREF-0
and
UNRESOLVED XREF-0.
The amount of memory currently in use by STREAMS, and the maximum amount used since the system was started are shown at the bottom of the output from netstat -m.
The figure for the total memory configured for use by STREAMS represents an upper limit to the amount of memory that can be dynamically allocated for use.
If there are several non-zero entries in the fail column
and the amount of memory in use by STREAMS is almost the
same as the total amount of memory configured for STREAMS,
increase the value of NSTRPAGES.
This parameter controls the number of 4KB pages
of physical memory
that can be dynamically allocated for use by STREAMS.
The following table summarizes the commands that you can use to examine STREAMS usage:
Examining STREAMS performance
| Command | Field | Description |
|---|---|---|
| netstat -m | fail | number of times a STREAMS resource was unavailable |
The TCP/IP protocol suite consists of the Transmission Control Protocol (TCP), the Internet Protocol (IP), and other protocols described in ``TCP/IP''. The TCP/IP protocol suite is implemented using STREAMS. You should ensure that sufficient STREAMS resources are available for networking to function correctly as described in ``STREAMS resources''.
See also:
The IP protocol stack is configured to maximize performance on all supported network adapters. If desired, you can further adjust performance parameters for each network interface using the ifconfig(ADMN) command as described in ``Using ifconfig to change parameters for a network card''. This command allows you to adjust:
With modern Ethernet hardware, you should use full frames to maximize the amount of data per Ethernet frame. On older Ethernet cards with small buffers and narrow data paths, rounding down should be selected to enable the data in the Ethernet frame to be moved into the card's buffer more efficiently.
Token Ring networks have a much larger MTU than Ethernet; full frames should always be used.
Problems with TCP/IP may be experienced if:
See also:
The most useful command for examining TCP/IP performance (and that of other protocol stacks) is netstat(TC). This command displays the contents of various networking-related data structures held in the kernel.
The command netstat -i displays the status of the system's network interfaces. (To view only a single interface, specify this using the -I option.) The output from this command has the following form:
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Collis sme0 1500 reseau paris 996515 0 422045 42 0 lo0 2048 loopback loopback 25436 0 25436 0 0The important fields are
Ierrs, Oerrs,
and Collis.
Ierrs is the number of received packets that the system recognized
as being corrupted. This usually indicates faulty network hardware such
as a bad connector, incorrect termination (on Ethernet), but it may also
be caused by packets being received for an unrecognized protocol.
For network adapters with small buffers, it may mean
that they have been saturated by end-to-end streams of packets. In this
case, you should switch the network interface to one-packet mode using
the
ifconfig(ADMN)
command as described in
``Using ifconfig to change parameters for a network card''.
Oerrs is the number of errors that occurred while the system
was trying to transmit a packet.
This generally indicates a connection problem.
On Ethernet, it may also indicate a prolonged period of time
during which the network is unusable due to packet collisions.
Collis is the number of times that the system
(connected to a network using Ethernet as its physical medium)
detected another starting to transmit while it was already transmitting.
Such an event is called a packet collision.
The ratio of the number of
collisions to the number of output packets transmitted gives a indication
of the loading of the network. If the number of Collis
is greater than 10% of pkts for the
most heavily used systems on the network, you should investigate
partitioning the network as described in
``Configuring network topology for performance''.
Networks implemented using
Token Ring and FDDI technology use a
different protocol to communicate at the physical
layer and do not experience packet collisions.
The value in the Collis field should be
zero for such networks.
See ``Troubleshooting TCP/IP'' for a full discussion of these issues.
The following table summarizes the commands that you can use to examine the performance of TCP/IP:
Examining TCP/IP performance
| Command | Field | Description |
|---|---|---|
| netstat -i | Ipkts | number of network packets received |
| Ierrs | number of corrupted network packets received | |
| Opkts | number of network packets transmitted | |
| Oerrs | number of errors while transmitting packets | |
| Collis | number of packet collisions detected |
If TCP/IP is configured, your system runs the /etc/rc2.d/S85tcp script each time it goes to multiuser mode. (Note that this file is a link to /etc/tcp.) This script starts several TCP/IP daemons. If configured to run, the following daemons may affect performance:
The Serial Line Interface Protocol (SLIP) is no longer supported.
To maximize performance of a connection over a PPP link, do the following:
For a complete discussion of using PPP, see ``Configuring the Point-to-Point Protocol (PPP)''.
The ping(ADMN) command is useful for seeing if a destination machine is reachable across a local area network (LAN) or a wide area network (WAN). If you are root, you can use the flood option, -f, on a LAN. This sends a hundred or more packets per second and provides a stress test of the network connection. For every packet sent and received, ping prints a period (.) and a backspace respectively. If you see several periods being printed, the network is dropping packets.
If you want to find out how packets are reaching a destination and how long this takes, use the traceroute(ADMN) command. This provides information about the number of hops needed, the address of each intermediate gateway, and the maximum, minimum and average round trip times in milliseconds. On many hop connections, you may need to increase the maximum time-to-live (TTL) and wait times for the probe packets that traceroute sends out. To do this, use the -m and -w options.
See also:
The types and capabilities of Ethernet network technology (as defined by the IEEE 802.3 standard) are shown in the following table:
Ethernet network technologies
| Type | Topology and | Maximum segment | Maximum number |
|---|---|---|---|
| and alternative names | medium | length | of nodes per segment |
| 10Base5, ThickNet | linear, 50 ohm 10mm coaxial cable terminated at both ends | 500m | 100 |
| 10Base2, ThinNet, CheaperNet | linear, 50 ohm 5mm coaxial cable terminated at both ends | 185m | 30 |
| 10Base-T, twisted pair | star, unshielded twisted pair | 100m | 2 |
To attach nodes to the network, 10Base5 connects drop cables to vampire taps directly attached to the coaxial cable or to transceiver boxes placed in line with the cable.
10Base2 T-piece connectors must be connected directly to the coaxial terminal of the network card -- that is, you cannot use a coaxial cable as a drop cable.
If you want to extend the length of an Ethernet cable segment, there are three ways of doing this:
If there are a large number of input or output errors, suspect the network hardware of causing problems. Reflected signals can be caused by cable defects, incorrect termination, or bad connections. A network cable analyzer can be used to isolate cable faults and detect any electrical interference.
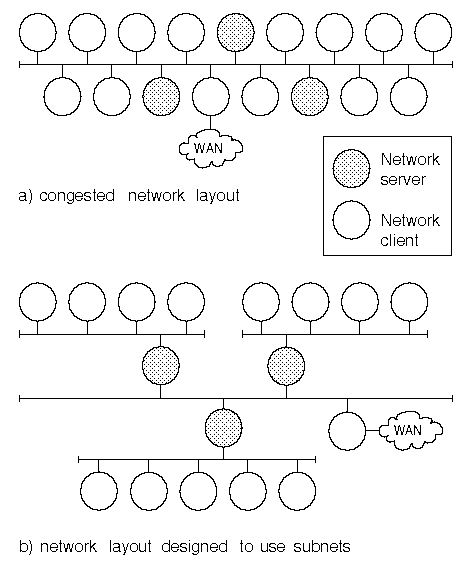
Dividing a network into subnetworks to reduce network traffic
To reduce network loading, consider dividing it into separate networks (subnets) as shown in ``Dividing a network into subnetworks to reduce network traffic''. This diagram shows how a network could be divided into three separate subnets. Routers connect each subnet to a backbone network. This solution only makes sense if you can group clients with individual servers by the function they perform. For example, you could arrange that each subnet corresponds to an existing department or project team within an organization. The clients dependent on each server should live on the same subnet for there to be a gain in network performance. If many machines are clients of more than one server, this layout may actually make the situation worse as it will impose an additional load on the servers acting as routers.
An alternative would be to use bridges to connect the network segments though this may be a more expensive solution. A potential problem with this is that if a bridge fails, the connection between the two segments is severed.
By connecting subnets using more than one router, you can provide an alternative route in case of failure of one of the routers. Another problem with using bridges is that they are intended to partially isolate network segments -- they are not a solution if you want to provide open access to all available services.
Design the layout of subnets to reflect network usage. Typically, each subnet will contain at least one server of one or more of the following types:
If you run client-server applications across repeaters, bridges, or routers, you should be aware that this will impose additional delay in the connection. This delay is usually least for repeaters, and greatest for routers.
See also:
There are few performance issues concerned with routing. Choice of routes outside your system is not generally in your control so this discussion only considers routing within an autonomous network.
Most networks use the Routing Information Protocol (RIP) for internal routing. RIP uses a metric for choosing a route based on distance as a number of hops. This metric is not optimal in certain circumstances. For example, it would choose a path to the desired destination over a slow serial link in preference to crossing an Ethernet and a Token Ring. You can increase the hop count on the slow interface advertised in the /etc/gateways file to overcome this limitation. The RIP protocol is available with both the routed(ADMN) and gated(ADMN) routing daemons.
Most networks tend to use routed as it requires no configuration. However, we recommend that you only use RIP for simple network topologies. The Open Shortest Path First (OSPF) protocol is better suited than RIP for complex networks with many routers because it has a more sophisticated routing metric. It can also group networks into areas. The routing information passed between areas uses an abstracted form of internal routing information to reduce routing traffic. OSPF is only available using the gated routing daemon.
You can use the Internet Router Discovery (IRD) protocol for routing within networks in autonomous systems. This is not a true routing protocol but it allows hosts connected to a multicast or broadcast network to discover the IP addresses of routers using ICMP messages. Routers can also use the protocol to make themselves known. The irdd(ADMN) daemon uses the IRD protocol and is normally configured to run by default in addition to routed.
You can minimize the routing traffic on your network by configuring:
The Domain Name Service server included with TCP/IP can operate in a number of modes, each of which has its own performance implications.
A primary or secondary DNS nameserver maintains and accesses potentially large databases, answers requests from other servers and clients, and performs zone transfers. Both network traffic and memory are impacted.
There are several ways in which you can influence the performance of primary and secondary DNS nameservers:
A DNS client pushes all resolution requests onto one or more DNS servers on the network; none are handled locally. This puts the burden of resolution on the network and on the nameservers listed in resolv.conf. It also means that named does not run and, therefore, does not add to the system load. In the case where the local machine has limited memory and response time over the network ranges from adequate to excellent, this configuration is desirable from a performance standpoint. If network response time is slow and memory is not limited, consider re-configuring the system as a caching-only server.
See also:
The Network File System (NFS) software allows one computer (an NFS client) attached to a network to access the filesystems present on the hard disk of another computer (an NFS server) on the network. An NFS client can mount the whole or part of a remote filesystem. It can then access the files in this filesystem almost as if they were present on a local hard disk.
See Configuring and administering NFS for NFS setup and performance tuning information.
The Network Information Service (NIS) supplements NFS and provides a distributed database of commonly accessed administration files. A master NIS server holds information files needed by all machines on the network centrally; examples of these files are /etc/passwd, /etc/group, and /etc/services. Whenever this information is updated, it is pushed out to slave servers and copy-only servers to ensure that it is updated globally.
NIS clients, which may be diskless, request information from servers whenever needed. This may be quite a common occurrence. For example, a command such as ls -l requires access to information held in the files /etc/passwd and /etc/group so that it can display the user and group ownership of files. If you are running NIS clients on your network, you should be aware that a proportion of network traffic will be caused by NIS clients requesting such information.
This chapter is of interest to application programmers who need to investigate the level of activity of system calls on a system.
System calls are used by programs and utilities to request services from the kernel. These can involve passing data to the kernel to be written to disk, finding process information and creating new processes. By allowing the kernel to perform these services on behalf of an application program, they can be provided transparently. For example, a program can write data without needing to be concerned whether this is to a file, memory, or a physical device such as disk or tape. It also prevents programs from directly manipulating and accidentally damaging system structures.
System calls can adversely affect performance because of the overhead required to go into system mode and the extra context switching that may result.
System call activity can be seen with rtpm and with sar -c, both of which return similar information, as in the following example sar -c output:
14:00:00 scall/s sread/s swrit/s fork/s lwpcr/s exec/s rchar/s wchar/s 14:20:00 285 41 10 0.03 0.00 0.03 3456 1708 14:40:00 260 25 10 0.03 0.00 0.03 2608 1642 15:00:36 8407 2014 2082 0.13 0.00 0.12 1287963 1378872 15:20:17 11529 2513 2752 0.09 0.00 0.06 2757132 3027665 15:40:21 10265 2643 2359 0.09 0.00 0.06 2144705 1877860 16:01:34 10876 2499 2536 0.08 0.00 0.05 242370 291737 16:20:05 11220 2805 2780 0.09 0.00 0.06 3336866 3326786 16:40:05 11052 2185 2086 0.08 0.00 0.06 356519 280317 17:00:00 3299 954 980 0.05 0.00 0.04 1789513 1844753 Average 7458 1739 1730 0.08 0.00 0.06 104928 117275
scall/s indicates the average number
of system calls per second averaged over the sampling interval.
Also of interest are sread/s
and swrit/s which indicate the number of
read(S)
and
write(S)
calls, and rchar/s and wchar/s which
show the number of characters transferred by them.
If you are an applications programmer and the SCO OpenServer Development System is installed on your system, you can use the tools described in the Debugging and Analyzing C and C++ Programs to examine application execution. Use the trace(CP) utility to investigate system call usage by a program.
Normally, read and write system calls
should not account for more than half of the total number
of system calls.
If the number of characters transferred
by each read (rchar/s / sread/s)
or write (wchar/s / swrit/s)
call is small, it is likely that some applications are
reading and writing small amounts of data for each system call.
It is wasteful for the system to spend much of its time switching
between
system
and
user mode
because of the overhead this incurs.
It may be possible to reduce the number of read and write calls by tuning the application that uses them. For example, a database management system may provide its own tunable parameters to enable you to tune the caching it provides for disk I/O.
fork/s and exec/s show the number of
fork(S)
and
exec(S)
calls per second.
If the system shows high fork and exec
activity, this may be due to it running a large number of shell
scripts. To avoid this, one possibility is to rewrite the shell
scripts in a high-level compiled language such as C.
You can use the sar -m command to see how many System V interprocess communication (IPC) message queue and semaphore primitives are issued per second. Note that you can also use the ipcs(ADM) command to report the status of active message queues, shared memory segments, and semaphores.
The tunables for IPC mechanisms are discussed in ``Inter-process communication (IPC) parameters''.
Semaphores are used to prevent processes from accessing the same resource, usually shared memory, at the same time.
The number of System V semaphores configured for use is controlled by the kernel parameter SEMMNI.
If the sema/s column
in the output from sar -m
shows that the number of semaphore primitives called
per second is high (for example, greater than 100),
the application may not be using IPC efficiently.
It is not possible to recommend a value here.
What constitutes a high number of semaphore calls depends on
the use to which the application puts them and the processing
power of the system running the application.
Messages are intended for interprocess communication which involves small quantities of data, usually less than 1KB. Between being sent and being received, the messages are stored on message queues. These queues are implemented as linked lists within the kernel.
Under some circumstances, you may need to increase resources allocated for messages and message queues above the default values defined in the mtune(F) file. Note that the kernel parameters defined in mtune set system-wide limits, not per-process limits.
Follow the guidelines below when changing the kernel parameters that control the configuration of message queues:
MSGSSZ
This value must be less than or equal to 128KB (131072 bytes).
The following table shows how to calculate the maximum values for these parameters based on the value of MSGSSZ. Note that MSGSSZ must be a multiple of 4 in the range 4 to 4096:
Calculation of maximum value of message parameters
| Parameter | Maximum value |
|---|---|
| MSGMAP | 131072 / MSGSSZ |
| MSGMAX | 32767 |
| MSGMNB | 65532 |
| MSGMNI | 1024 |
| MSGSEG | 131072 / MSGSSZ |
| MSGTQL | MSGMNB / MSGSSZ |
Shared memory is an extremely fast method of interprocess communication. As its name suggests, it operates by allowing processes to share memory segments within their address spaces. Data written by one process is available immediately for reading by another process. To prevent processes trying to access the same memory addresses at the same time, known as a race condition, the processes must be synchronized using a mechanism such as a semaphore.
The maximum number of shared-memory segments available for use is controlled by the value of the kernel parameter SHMMNI. The maximum size in bytes of a segment is determined by the value of the kernel parameter SHMMAX.
For more information on the kernel parameters that you can use to configure shared memory, see UNRESOLVED XREF-0 and UNRESOLVED XREF-0.
Reducing most system call activity is only possible if the source code for the programs making the system calls is available. If a program is making a large number of read and write system calls that each transfer a small number of bytes, then the program needs to be rewritten to make fewer system calls that each transfer larger numbers of bytes.
Other possible sources of system call activity are applications that use interprocess communication (semaphores, shared memory, and message queues), and record locking. You should ensure that the system has sufficient of these resources to meet the demands of the application. Most large applications such as database management systems include advice on tuning the application for the host operating system. They may also include their own tuning facilities, so you should always check the documentation that was supplied with the application.
A variety of tools are available to monitor system performance or report on the usage of system resources such as disk space, interprocess communication (IPC) facilities, and pipes:
When attempting to achieve optimal performance for the I/O subsystem, it is important to make sure that the disks have enough free space to do their job efficiently. The df(C) command, and its close relative dfspace(C), enable you to see how much free space there is. The following example shows the output from df and dfspace on the same system:
$The -i option to df also provides additional information about the number of free and used inodes.df/ (/dev/root ): 37872 blocks 46812 i-nodes /u (/dev/u ): 270814 blocks 36874 i-nodes /public (/dev/public ): 191388 blocks 55006 i-nodes /london (wansvr:/london ): 149750 blocks 0 i-nodes $dfspace/ : Disk space: 18.49 MB of 292.96 MB available ( 6.31%). /u : Disk space: 132.23 MB of 629.98 MB available (20.99%). /public : Disk space: 93.45 MB of 305.77 MB available (30.56%). /london : Disk space: 73.12 MB of 202.56 MB available (36.10%).Total Disk Space: 317.29 MB of 1431.29 MB available (22.17%). $
df -vMount Dir Filesystem blocks used free %used / /dev/root 600000 562128 37872 93% /u /dev/u 1290218 1019404 270814 79% /public /dev/public 626218 434830 191388 69% /london wansvr:/london 414858 265108 149750 63%
dfspace is a shell script interface to df. Without options, it presents the filesystem data in a more readable format than df. When used with its options, df provides more comprehensive information than dfspace.
In the above example, there are three local filesystems:
du(C) is another command that can be used to investigate disk usage. It differs from df and dfspace because it reports the number of 512-byte blocks that files and directories contain rather than the contents of an entire filesystem. If no path is specified, du reports recursively on files and directories in and below the current directory. Its use is usually confined to sizing file and directory contents.
The ps(C) command obtains information about active processes. It gives a ``snapshot'' picture of what processes are executing, which is useful when you are trying to identify what processes are loading the system. Without options, ps gives information about the login session from which it was invoked. If you use ps as user root, you can obtain information about all the system's processes. The most useful options are as follows:
ps options
| Option | Reports on: |
|---|---|
| -e | print information on all processes |
| -f | generate a full listing |
| -l | generate a long listing (includes more fields) |
| -u | print information on a specified user (or users) |
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 31 S 0 0 0 0 95 20 1f21 0 f0299018 ? 0:00 sched 20 S 0 1 0 0 66 20 252 40 e0000000 ? 30:37 init 31 S 0 2 0 0 95 20 254 0 f00c687c ? 0:01 vhand 31 S 0 3 0 0 81 20 256 0 f00be318 ? 5:19 bdflush ... 20 S 0 204 1 0 76 20 416 96 f023451a ? 1:56 cron 20 S 0 441 1 0 75 20 972 44 f01076b8 03 0:00 getty 20 S 20213 8783 1 0 73 20 1855 48 f011bae4 006 0:04 ksh 20 S 13079 25014 24908 0 75 20 155c 48 f010ee28 p4 0:01 ksh 20 R 13079 25016 24910 22 36 20 506 144 f010ed58 p2 0:03 vi 20 S 12752 27895 26142 0 73 20 7b0 40 f011f75c 010 0:00 sh 20 Z 13297 25733 25153 0 51 20 0:00 <defunct> 20 R 13297 26089 25148 45 28 20 8a8 48 f012123c p12 0:01 ksh 20 S 12752 26142 1 0 73 20 1ce2 48 f01214ec 010 0:04 csh 20 R 12752 28220 27898 55 25 20 1e16 188 f010f6b0 p25 0:01 email 20 S 12353 27047 25727 0 73 20 161c 44 f012179c p13 0:00 ksh 20 O 13585 28248 28205 36 37 20 cc9 92 p23 0:00 ps 20 S 20213 28240 8783 0 75 20 711 140 f01156f8 006 0:00 vi ...
The field headed F gives information
about the status of a process as a combination of
one or more octal flags. For example,
the sched process at the top has a setting of 31 which is the
sum of the flags 1, 10 and 20. This means that the sched process
is part of the kernel (1), sleeping at a priority of 77 or more (10), and
is loaded in primary memory (20). The priority is confirmed by consulting
the PRI field further along the line which displays a priority
of 95.
In fact both sched (the swapper) and vhand (the paging
daemon) are inactive but have the highest possible priority. Should either
of them need to run in the future they will do so at the context switch
following their waking up as no other process will have a higher
priority. For more information on the octal flags displayed and their
interpretation see
ps(C).
The S column shows the state of each process.
The states shown in the
example: S, R, O and Z
mean sleeping (waiting for an event), ready-to-run, on the processor
(running) and zombie (defunct) respectively.
There is only one process running, which
is the ps command itself
(see the penultimate line).
Every other process is either waiting to run or waiting
for a resource to become available. The exception is
the zombie
process which is currently terminating;
this entry will only disappear from the
process table if the parent issues a
wait(S)
system call.
The current priority of a process is also a useful indicator of what a
process is doing. Check the value in the PRI field
which can be interpreted as shown in the following table:
Priority values
| Priority | Meaning |
|---|---|
| 95 | swapping/paging |
| 88 | waiting for an inode |
| 81 | waiting for I/O |
| 80 | waiting for buffer |
| 76 | waiting for pipe |
| 75 | waiting for tty input |
| 74 | waiting for tty output |
| 73 | waiting for exit |
| 66 | sleeping -- lowest system mode priority |
| 65 | highest user mode priority |
| 51 | default user mode priority |
| 0 | lowest user mode priority |
The C field indicates the recent usage of
CPU time by a process. This is useful for
determining those processes which are making a machine slow
currently.
The NI field shows the
nice value
of a process. This directly
affects the calculation of its priority when it is being scheduled.
All processes in the above example are running with the default
nice value of 20.
The TIME field shows the minutes and seconds of
CPU time used by processes. This is useful for seeing
if any processes are CPU hogs, or runaway, gobbling up
large amounts of CPU time.
The SZ field shows the swappable size
of the process's data and stack in 1KB units.
This information is of limited use in determining how much
memory is currently occupied by a process as it does
not take into account how much of the reported
memory usage is shared.
Totaling up this field for all memory resident processes will not
produce a meaningful figure for current memory usage.
It is useful on a per process basis as you can use it to
compare the memory usage of different versions of an
application.
sar(ADM) provides information that can help you understand how system resources are being used on your system. This information can help you solve and avoid serious performance problems on your system.
The individual sar options are described on the sar(ADM) manual page.
For systems with an SCO SMP License, mpsar(ADM) reports systemwide statistics, and cpusar(ADM) reports per-CPU statistics.
The following table summarizes the functionality of each sar, mpsar, and cpusar option that reports an aspect of system activity:
sar, cpusar, and mpsar options
| Option | Activity reported |
|---|---|
| -a | file access operations |
| -A | summarize all reports |
| -b | buffer cache |
| -B | copy buffers |
| -c | system calls |
| -d | block devices including disks and all SCSI peripherals |
| -F | floating point activity (mpsar only) |
| -g | serial I/O including overflows and character block usage |
| -h | scatter-gather and physical transfer buffers |
| -I | inter-CPU interrupts (cpusar and mpsar only) |
| -j | interrupts serviced per CPU (cpusar only) |
| -L | latches |
| -m | System V message queue and semaphores |
| -n | namei cache |
| -O | asynchronous I/O (AIO) |
| -p | paging |
| -q | run and swap queues |
| -Q | processes locked to CPUs (cpusar and mpsar only) |
| -r | unused memory and swap |
| -R | process scheduling |
| -S | SCSI request blocks |
| -u | CPU utilization (default option for all sar commands) |
| -v | kernel tables |
| -w | paging and context switching |
| -y | terminal driver including hardware interrupts |
System activity recording is disabled by default on your system. If you wish to enable it, log in as root, enter the command /usr/lib/sa/sar_enable -y, then shut down and reboot the system. See sar_enable(ADM) for more information.
Once system activity recording has been started on your system, it measures internal activity using a number of counters contained in the kernel. Each time an operation is performed, this increments an associated counter. sar(ADM) can generate reports based on the raw data gathered from these counters. sar reports provide useful information to administrators who wish to find out if the system is performing adequately. sar can either gather system activity data at the present time, or extract historic information collected in data files created by sadc(ADM) (System Activity Data Collector) or sa1(ADM).
If system activity recording has been started, the following crontab entries exist for user sys in the file /usr/spool/cron/crontabs/sys:
0 * * * 0-6 /usr/lib/sa/sa1 20,40 8-17 * * 1-5 /usr/lib/sa/sa1The first sa1 entry produces records every hour of every day of the week. The second entry does the same but at 20 and 40 minutes past the hour between 8 am and 5 pm from Monday to Friday. So, there is always a record made every hour, and at anticipated peak times of activity recordings are made every 20 minutes. If necessary, root can modify these entries using the crontab(C) command.
The output files are in binary format (for compactness) and are stored in /usr/adm/sa. The filenames have the format sadd, where dd is the day of the month.
To record system activity every t seconds for n intervals and save this data to sar_data, enter sar -o datafile t n.
For example, to collect data every 60 seconds for 10 minutes into
the file /tmp/sar_data on a single CPU
machine, you would enter:
sar -o /tmp/sar_data 60 10
To examine the data from datafile, the
sar(ADM)
command is:
sar [ option ... ] [ -f datafile ]
and the
mpsar(ADM)
and
cpusar(ADM)
commands are:
mpsar [ option ... ] [ -f datafile ]
cpusar [ option ... ] [ -f datafile ]
Each option specifies the aspect of system activity
that you want to examine.
datafile is the
name of the file that contains the statistics you want to view.
For example, to view the sar -v report for
the tenth day of the most recent month, enter:
sar -v -f /usr/adm/sa/sa10
You can also run sar to view system activity in ``real time''
rather than examining previously collected data.
To do this, specify the sampling interval in seconds followed by the
number of repetitions required.
For example, to take 20 samples at an interval of 15 seconds, enter:
sar -v 15 20
As shipped, the system allows any user to run sar in real time. However, the files in the /usr/adm/sa directory are readable only by root. You must change the permissions on the files in that directory if you want other users to be able to access sar data.
With certain options, if there is no information to display in any of the relevant fields after a specified time interval then a time stamp will be the only output to the screen. In all other cases zeros are displayed under each relevant column.
When tuning your system, we recommend that you use a benchmark and have the system under normal load for your application.
Swap space is secondary disk storage that is used when the system considers that there is insufficient main memory. On a well-configured system, it is primarily used for processing dirty pages when free memory drops below the value of the kernel parameter GPGSLO. If memory is very short, the kernel may swap whole processes out to swap. Candidates for swapping out are processes that have been waiting for an event to complete or have been stopped by a signal for more than two seconds. If a process is chosen to be swapped out then its stack and data pages are written to the swap device. (Initialized data and program text can always be reread from the original executable file on disk).
The system comes configured with one swap device. Adding additional swap devices with the swap(ADM) command makes more memory available to user processes. Swapping and excessive paging degrade system performance but augmenting the swap space is a way to make more memory available to executing processes without optimizing the size of the kernel and its internal data structures and without adding physical memory.
The following command adds a second swap device,
/dev/swap1, to the system.
The swap area starts 0 blocks into the swap device
and the swap device is 16000 512-byte blocks in size.
swap -a /dev/swap1 0 16000
Use the swap -l command to see statistics about all the swap devices currently configured on the system. You can also see how much swap is configured on your system at startup by checking nswap. This is listed in the configuration and diagnostic file /usr/adm/messages as a number of 512-byte blocks.
Running the swap -a command adds a second swap device only until the system is rebooted. To ensure that the second swap device is available every time the system is rebooted, use a startup script in the /etc/rc2.d directory. For example, you could call it S09AddSwap.
In this release, a swap area can also be created within a filesystem to allow swapping to a file. To do this, you must marry a block special device to a regular file. For more information, see swap(ADM) and marry(ADM).
timex(ADM) times a command and reports the system activities that occurred on behalf of the command as it executed. Run without options it reports the amount of real (clock) time that expired while the command was executing and the amount of CPU time (user and system) that was devoted to the process. For example:
# timex command command_options
real 6:54.30
user 53.98
sys 14.86
Running timex -s is roughly equivalent
to running sar -A,
but it displays system statistics only from when you
issued the command until the command finished executing.
If no other programs are running,
this information can help identify which resources a specific
command uses during its execution.
System consumption can be collected
for each application program and used for
tuning the heavily loaded resources.
Other information is available if the process accounting software is installed; see
timex(ADM)
for more information.
timex belongs to a family of commands that report command resource usage. It can be regarded as an extension to time(C) which has no options and produces output identical to timex without options. If you wish to use time then you must invoke it by its full pathname as each of the Bourne, Korn and C shells have their own built-in version. The output from each of the shell built-ins varies slightly but is just as limited. The C shell, however, does add in average CPU usage of the specified command.
The vmstat(C) command is no longer supported. Instead, rtpm(ADM) (the MEMORY and PAGING/s sections) and sar -K udk -gkprw.
You can adjust the configuration parameters for TCP/IP using the ifconfig(ADMN) and inconfig(ADMN) utilities.
If you need to change STREAMS resources, you must use the configure(ADM) idtune(ADM) or SCOadmin System Tuner.
You can use the ifconfig(ADMN) command to reconfigure performance parameters for a single network interface. If you wish to make this change permanent you must edit the entry for the interface in the /etc/tcp script.
The metric, onepacket, and perf parameters affect performance.
metric can be used to artificially raise the routing
metric of the interface used by the routing daemon,
routed(ADMN).
This has the effect of making a route using this interface less
favorable.
For example, to set the metric for the sme0
interface to 10, enter:
/etc/ifconfig sme0 inet metric 10
onepacket enables one-packet at a time operation for
interfaces with small buffers that are unable to handle continuous
streams of back-to-back packets. This parameter takes two
arguments that allow you to define a small packet size, and the
number of these that you will permit in the receive window.
This deals with TCP/IP implementations that can send
more than one packet within the window size for the connection.
Set the small packet size and count to zero if you are not
interested in detecting small packets. For example, to set
one-packet mode with a small
packet threshold of one small packet of 512 bytes on
the e3A0 interface, enter:
/etc/ifconfig e3A0 inet onepacket 512 1
To turn off one-packet mode for this interface, enter:
/etc/ifconfig e3A0 inet -onepacket
perf allows you to tune performance parameters on a per-interface basis. The arguments to perf specify the receive and send window sizes in bytes, and whether TCP should restrict the data in a segment to a multiple of 1KB (a value of 0 restricts; 1 uses the full segment size).
The following example sets the receive and send window size to
4KB, and uses the maximum 1464-byte data size available in an
Ethernet frame:
/etc/ifconfig sme0 inet perf 4096 4096 1
As root, you can use the inconfig(ADMN) command to change the global default TCP/IP configuration values.
For example, to enable forwarding of IP
packets, you would enter:
inconfig ipforwarding 1
inconfig updates the values of the parameters defined in /etc/default/inet and those in use by the currently executing kernel. You do not need to reboot your system for these changes to take effect; inconfig dynamically updates the kernel with the changes you specify. Before doing so, it verifies that the values you input are valid. If they are not, the current values of the parameters are retained.
See ``Networking parameters'' for a description of the TCP/IP parameters that you can tune using inconfig.